|
I collect data, train models and measure their effectiveness in solving real-world problems. I have studied multimodal representation learning and generative modeling in Seoul National University, under the supervision of prof. Nojun Kwak. Currently I am working on large-scale video-language model training and agent applications at Twelve Labs. Previously, I was immersed in AI-driven sleep interpretation task (sleep sound to human-readable report) at ASLEEP and high-precision commercial image generation at NXN Labs. Email / CV / Google Scholar / Github |

|
|
|
|
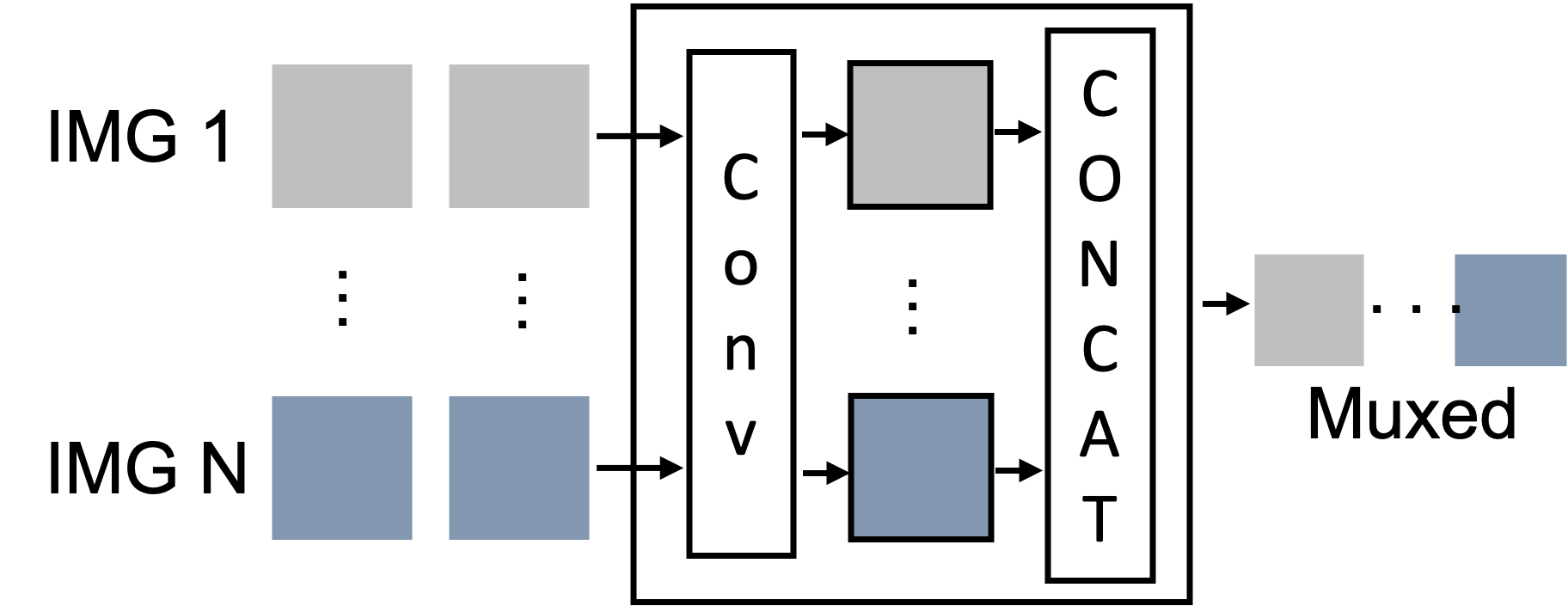
Donghoon Han, Seunghyeun Seo, Donghyeon Jeon, Jiho Jang, Chaerin Kong, Nojun Kwak NeurIPS 2023 Workshop on Advancing Neural Network Training (Oral) arXiv We explore means to accelerate ViT inference by concatenating abstract visual tokens of multiple images along dim=1 and processing them at once. |
|
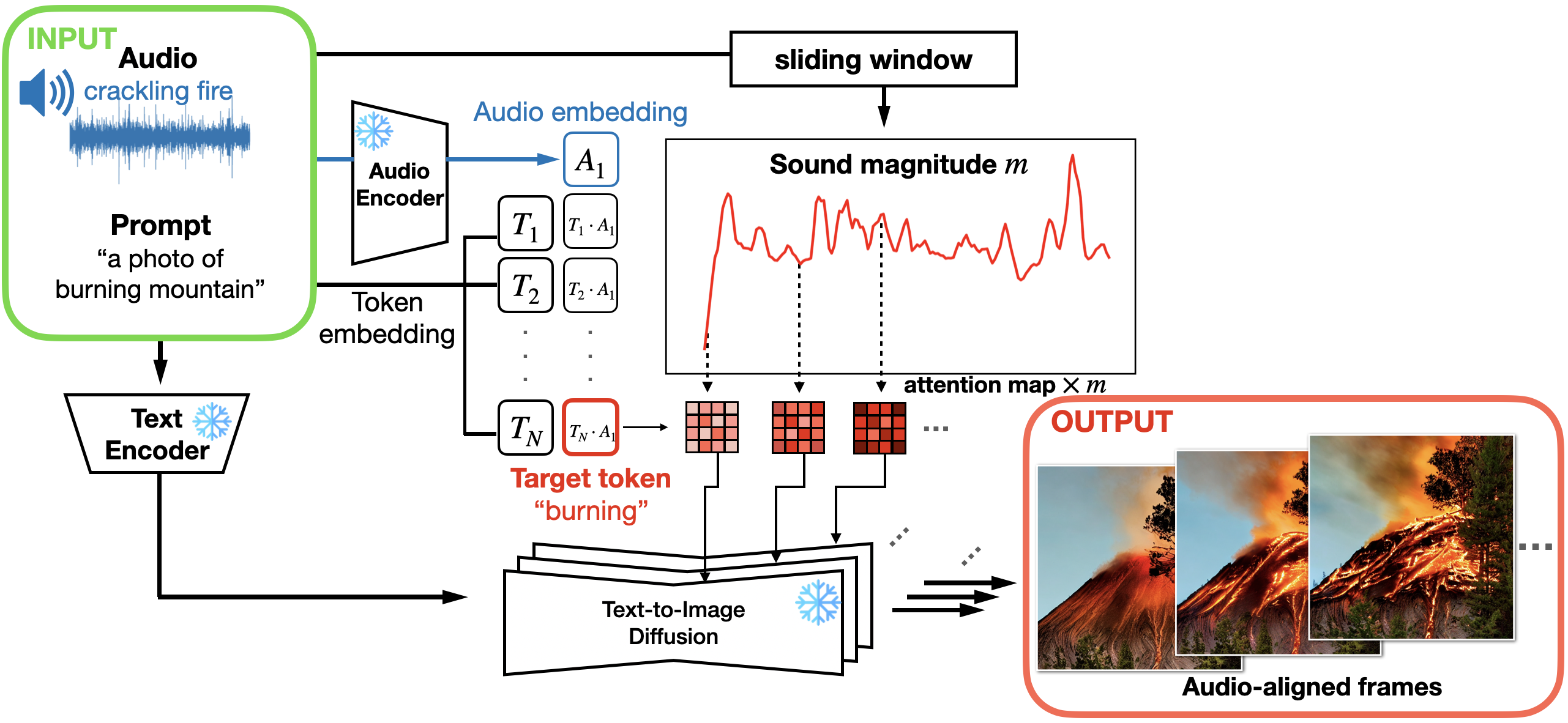
Seungwoo Lee, Chaerin Kong, Donghyeon Jeon, Nojun Kwak CVPR 2023 Workshop on AI for Content Creation arXiv We introduce a simple framework for audio-aligned text-to-video synthesis that employs an off-the-shelf text-to-image diffusion model. |

|
Chaerin Kong, Nojun Kwak ICLR 2023 Workshop on Multimodal Representation Learning (Spotlight) arXiv / poster We study the semantic information encoded in widely used Vision-Language objectives (e.g., contrastive, captioning) by using each as diffusion guidance and inspecting the visualized images. |
|
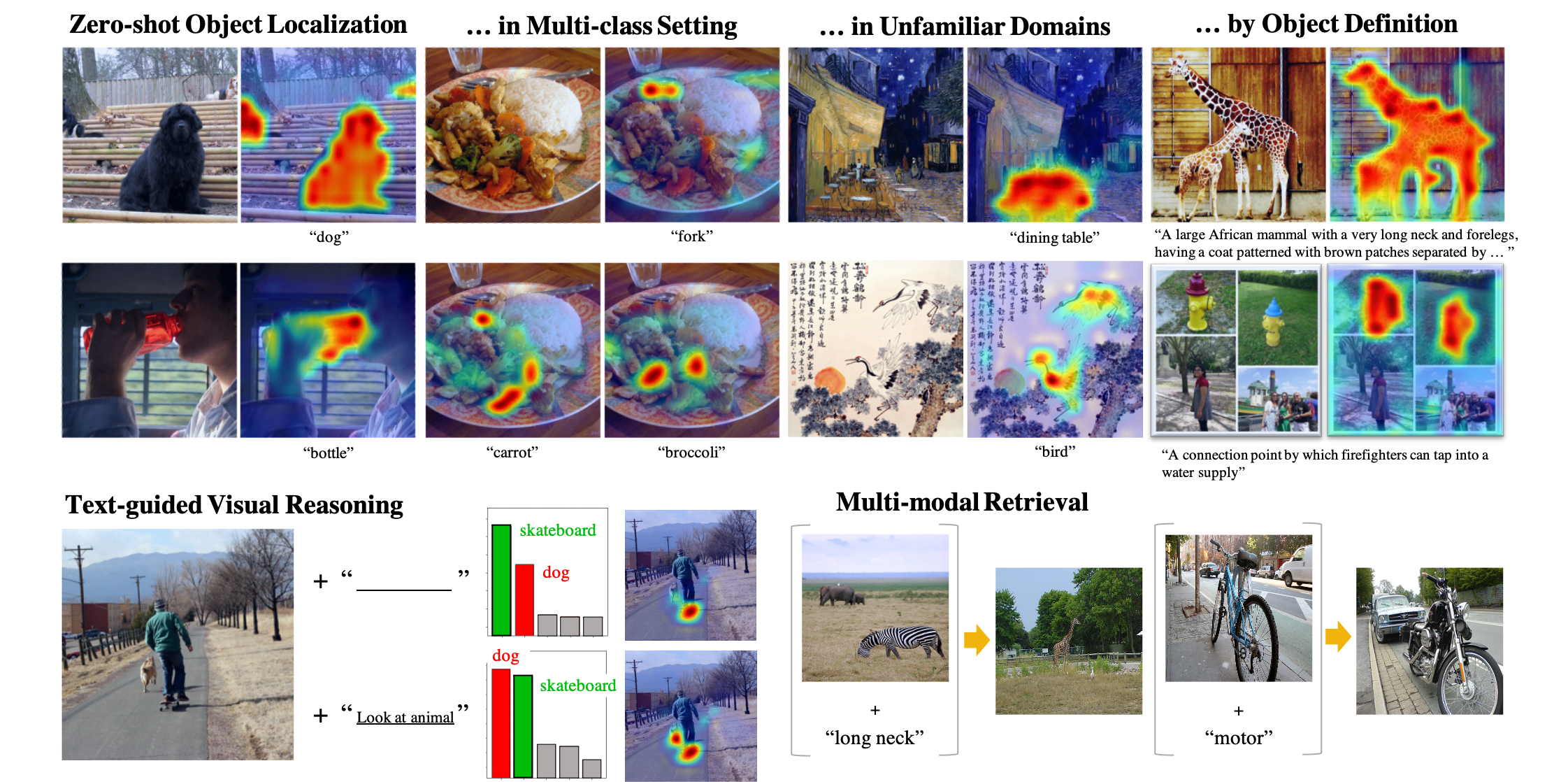
Jiho Jang*, Chaerin Kong*, Donghyeon Jeon, Seonhoon Kim, Nojun Kwak AAAI 2023 (Oral) arXiv / poster We train a modality-agnostic Vision-Language model, OneR, and investigate intriguing properties of a unified V-L representation. |

|
Chaerin Kong, Donghyeon Jeon, Ohjoon Kwon, Nojun Kwak WACV 2023 arXiv / poster We propose a mask-free fashion attribute editing framework that employs a pretrained diffuser and an efficiently finetuned guidance model. |
|
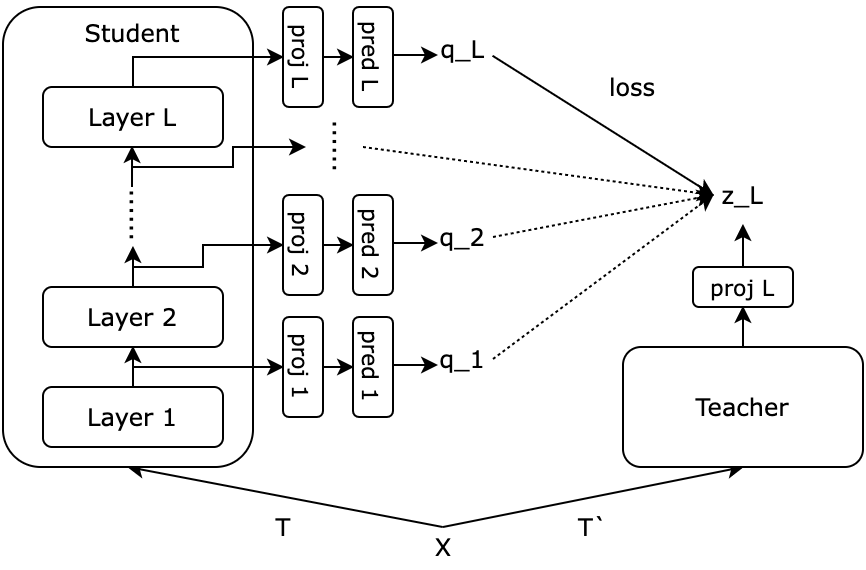
Jiho Jang, Seonhoon Kim*, KiYoon Yoo*, Chaerin Kong, Jangho Kim, Nojun Kwak WACV 2023 By encouraging self-distillation from lower layer to upper layer in traditional SSL frameworks (e.g., SimCLR, MoCo, BYOL), we can improve the representation quality as confirmed by various downstream task performances. |
|
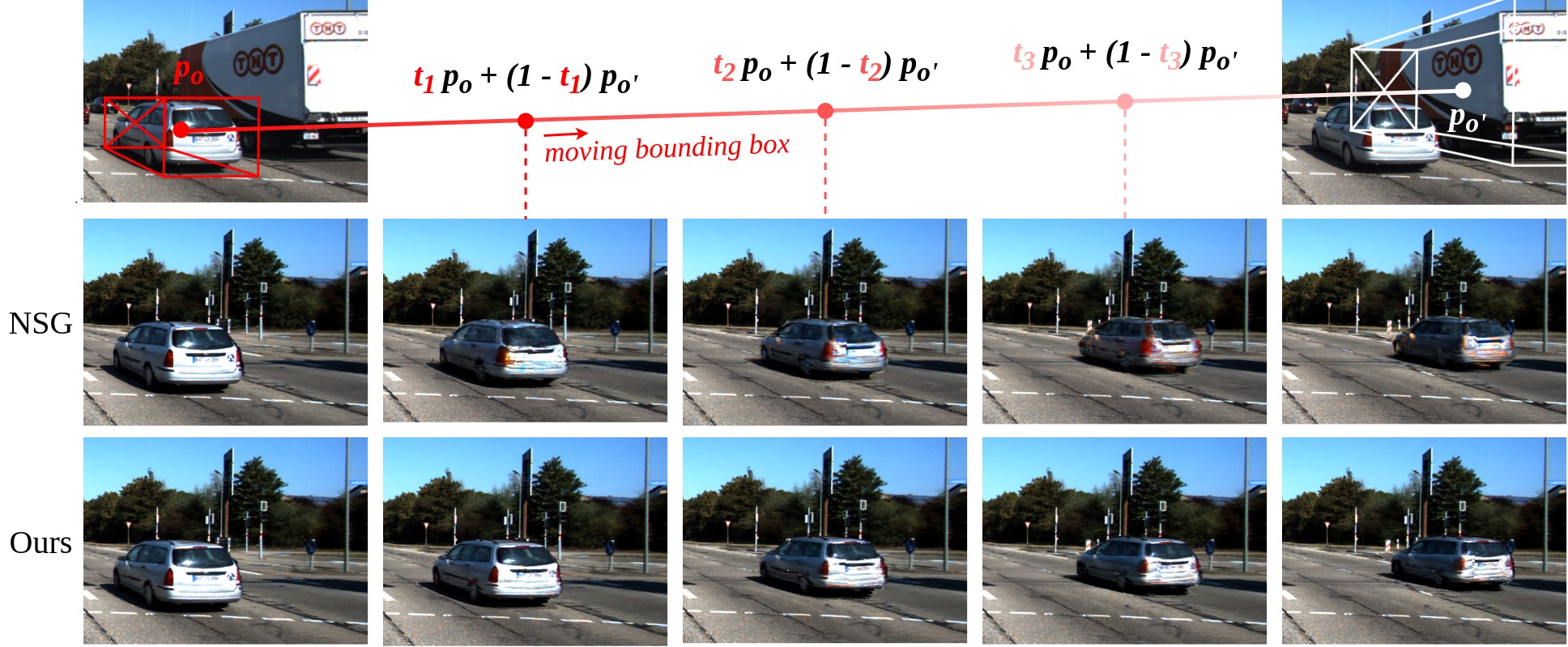
Yeji Song, Chaerin Kong, Seo Young Lee, Nojun Kwak, Joonseok Lee BMVC 2022 code / arXiv Neural Scene Graphs can be rendered more efficiently and in a more controllable manner by learning the consistency field of a given scene. |

|
Chaerin Kong, Jeesoo Kim, Donghoon Han, Nojun Kwak ECCV 2022 code / arXiv / poster Instead of directly combatting memorization for few-shot (n<100) image synthesis, we propose latent space smoothing regularizations that empower the generator to produce diverse (perceptually continuous) set of samples. |
{kind=link}
|
|

|
Chaerin Kong*, Seungyong Lee* Soohyeok Im* Wonsuk Yang* arXiv We achieve high fidelity text-driven fashion style editing in a compute-efficient manner by leveraging a generative human prior. |
|
Chaerin Kong, Nojun Kwak arXiv We tackle the challenging task of few-shot incremental image synthesis by training a knowledge-preserving (conservative) generator and semantic learning (progressive) discriminator. |
|
The template is from Jon Barron. Thank you for sharing! |